Object Detection Tutorial on notebook (pytorch)
はじめる前に
このチュートリアルを始める前に、以下のKAMONOHASHIのインストールが終わり、KAMONOHASHIにログインできることを確認してください。
(参考) KAMONOHASHIをインストールする
はじめに
本チュートリアルでは、Penn- Fudan Databaseの歩行者の検出を行います。 具体的にはKAMONOHASHI上のJupyterLabを使用して、Deep Learningでの物体検知をPenn-Fudan データセットで行う方法を以下の手順に沿って説明します。
- データをアップロードする
- データセットを作成する
- ノートブックを作成し、JupyterLabを起動する
- 人物検出のモデル学習・推論を行う
データをアップロードする
KAMONOHASHIにデータをアップロードする流れを説明します。
データセットをダウンロードする
このチュートリアルでは、Penn-Fudanデータセットlaunchを使用します。 Penn-Fudanは、歩行者の検出に使用される画像データベースです。 170枚の画像に345のラベルが付けられた歩行者が含まれており、そのうち96枚の画像はペンシルベニア大学周辺、他の74枚は復旦大学周辺で撮影されています。
KAMONOHASHIにアクセスできる端末に Penn-Fudanデータセット をダウンロードしてください。 Penn-Fudanのデータをダウンロードするsave_alt
データを解凍する
このデータセットは解凍すると、
PennFudanPed/
PedMasks/
FudanPed00001_mask.png
FudanPed00002_mask.png
FudanPed00003_mask.png
FudanPed00004_mask.png
...
PNGImages/
FudanPed00001.png
FudanPed00002.png
FudanPed00003.png
FudanPed00004.png
というフォルダ・ファイルに分割されます。
データをKAMONOHASHIにアップロードする
データが用意できたらKAMONOHASHIにアップロードしましょう。 [データ管理]を選択し、右上の新規登録ボタンから行います。
| 種類 | 説明 |
|---|---|
| データ名 | (例)PNGImages |
| メモ | 画像の説明など補足情報。 |
| タグ | データの種類や受領日などグルーピングしたい単位に付与し、検索等で利用する。 |
| ファイル | 複数のデータを登録できる。jpg/png/csv/zipなど、ファイルのデータ形式は任意。 |
上記の情報を入力し、右下の登録ボタンを押すとデータをアップロードすることができます。 今回は、下記データ名でデータを登録することとします。
- PNGImages: PNGImages内に含まれる170枚の画像を登録します
- PedMasks: PedMasks内に含まれる170枚の画像を登録します。
登録したデータは、データの一覧画面で確認できます。 なおコマンドラインインターフェイス(CLI)を使用してデータをアップロードすることも可能です。
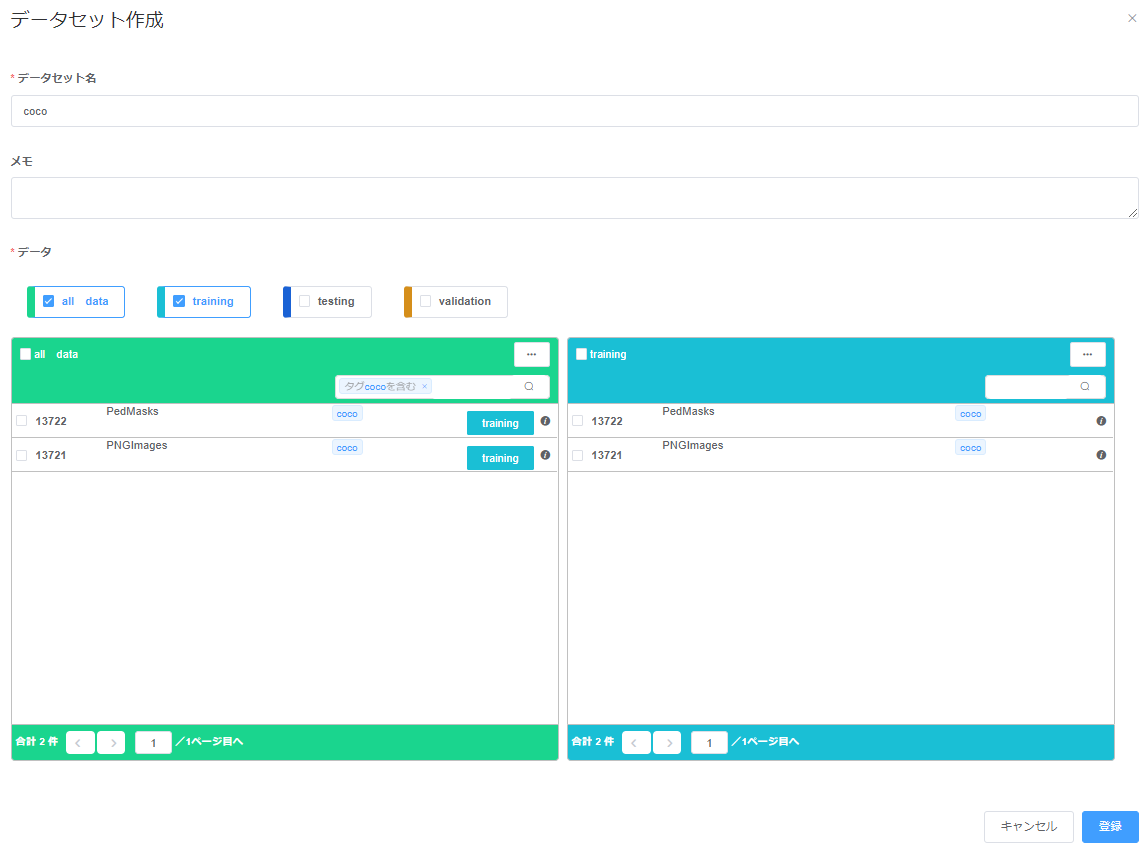
データセットを作成する
[データセット管理]を選択し、右上の新規登録ボタンから行います。 アップロードしたデータをtraining用にまとめます。
ノートブックを作成し、JupyterLabを起動する
KAMONOHASHIでノートブックを作成し、JupyterLabを起動します。
ノートブックを開始すると KAMONOHASHI はクラスタから指定されたCPU、メモリ、GPUリソースを確保し、JupyterLabを起動し計算環境を用意します。ユーザはこの環境を利用し、ノートブック形式で任意の計算を行うことができます。
GUIでノートブックを開始するには[ノートブック管理]を選択し、ノートブック作成ボタンから行います。 詳細はUser Guideを参照してください。
step1
ノートブック名を記入します。 半角英数小文字、または記号(“-”(ハイフン)) 30 文字以下で指定可能です。
step2
必要なリソース・起動時間を指定します。 以下は例です。
例
| リソース | 使用量 |
|---|---|
| CPU | 2 |
| Memory | 8 |
| GPU | 1 |
| 起動時間設定 | ON |
| 起動時間 | 8h |
step3
フレームワークとモデルをテキストエリアに記述し、実行コマンドを記述します。 本チュートリアルではフレームワークはDocker Hubの公式イメージ(pytorch/pytorch)を使用しています。
- コンテナイメージ
| コンテナイメージ | 記述例 |
|---|---|
| レジストリ | officail-docker-hub(選択) |
| イメージ | pytorch/pytorch |
| タグ | 1.3-cuda10.1-cudnn7-runtime |
※Docker Hubを指定した後イメージ、タグをテキストエリアに入力してください。
- データセット 上記で登録したデータセットを選択します。
step4
オプションとして追記したい項目があれば追記し実行ボタンを押します。
ステータスがRunningになったらJupyterLabを起動できます。
人物検出のモデル学習・推論を行う
notebook見本はGitHubから確認できます。
前準備
shell機能を利用し下記コマンドを実行することで、本機能で用いるファイルの準備を行います。
cd /kqi/output
# Install pycocotools
git clone https://github.com/cocodataset/cocoapi.git
git checkout 8c9bcc3cf640524c4c20a9c40e89cb6a2f2fa0e9
cd cocoapi/PythonAPI
pip install Cython
python setup.py build_ext install
make
# Download TorchVision repo to use some files from
# references/detection
git clone https://github.com/pytorch/vision.git
cd vision
git checkout v0.3.0
cp references/detection/utils.py ../
cp references/detection/transforms.py ../
cp references/detection/coco_eval.py ../
cp references/detection/engine.py ../
cp references/detection/coco_utils.py ../
ノートブックを作成する
ノートブックを開くボタンを押下し、ノートブック画面にアクセスします。 LauncherからNotebookのPython3を選択し、新規ノートブックを作成します。
データの確認を行う
KAMONOHASHIにアップロードしたデータの確認を行います。 データは/kqi/input配下にあります。
from PIL import Image
Image.open('/kqi/input/training/PNGImagesを入れたデータID/FudanPed00001.png')
データセットの定義をする
今回利用するAPIが格納されたディレクトリに移動します。
cd /kqi/output/cocoapi/PythonAPI
データセットの定義をします。
import os
import numpy as np
import torch
import torch.utils.data
from PIL import Image
class PennFudanDataset(torch.utils.data.Dataset):
def __init__(self, root, transforms=None):
self.root = root
self.transforms = transforms
# load all image files, sorting them to
# ensure that they are aligned
self.imgs = list(sorted(os.listdir(os.path.join(root, "PNGImagesを入れたデータID"))))
self.masks = list(sorted(os.listdir(os.path.join(root, "PedMasksを入れたデータID"))))
def __getitem__(self, idx):
# load images ad masks
img_path = os.path.join(self.root, "PNGImagesを入れたデータID", self.imgs[idx])
mask_path = os.path.join(self.root, "PedMasksを入れたデータID", self.masks[idx])
img = Image.open(img_path).convert("RGB")
# note that we haven't converted the mask to RGB,
# because each color corresponds to a different instance
# with 0 being background
mask = Image.open(mask_path)
mask = np.array(mask)
# instances are encoded as different colors
obj_ids = np.unique(mask)
# first id is the background, so remove it
obj_ids = obj_ids[1:]
# split the color-encoded mask into a set
# of binary masks
masks = mask == obj_ids[:, None, None]
# get bounding box coordinates for each mask
num_objs = len(obj_ids)
boxes = []
for i in range(num_objs):
pos = np.where(masks[i])
xmin = np.min(pos[1])
xmax = np.max(pos[1])
ymin = np.min(pos[0])
ymax = np.max(pos[0])
boxes.append([xmin, ymin, xmax, ymax])
boxes = torch.as_tensor(boxes, dtype=torch.float32)
# there is only one class
labels = torch.ones((num_objs,), dtype=torch.int64)
image_id = torch.tensor([idx])
area = (boxes[:, 3] - boxes[:, 1]) * (boxes[:, 2] - boxes[:, 0])
# suppose all instances are not crowd
iscrowd = torch.zeros((num_objs,), dtype=torch.int64)
target = {}
target["boxes"] = boxes
target["labels"] = labels
target["image_id"] = image_id
target["area"] = area
target["iscrowd"] = iscrowd
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.imgs)
データセットの確認を行います。
dataset = PennFudanDataset('/kqi/input/training/')
dataset[0]
結果
(<PIL.Image.Image image mode=RGB size=559x536 at 0x7F59B993C6A0>,
{'area': tensor([35358., 36225.]), 'boxes': tensor([[159., 181., 301., 430.],
[419., 170., 534., 485.]]), 'image_id': tensor([0]), 'iscrowd': tensor([0, 0]), 'labels': tensor([1, 1])})
モデルの定義を行う
物体検出のためモデルはFaster R-CNNを使用しています。
import torchvision
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# from torchvision.models.detection.mask_rcnn import MaskRCNNPredictor
def get_instance_segmentation_model(num_classes):
# load a model pre-trained pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# get the number of input features for the classifier
in_features = model.roi_heads.box_predictor.cls_score.in_features
# replace the pre-trained head with a new one
model.roi_heads.box_predictor = FastRCNNPredictor(in_features, num_classes)
return model
学習を行う
notebookでの操作
data augmentationや変換するための補助関数を定義します。
from engine import train_one_epoch, evaluate
import utils
import transforms as T
import matplotlib
def get_transform(train):
transforms = []
# converts the image, a PIL image, into a PyTorch Tensor
transforms.append(T.ToTensor())
if train:
# during training, randomly flip the training images
# and ground-truth for data augmentation
transforms.append(T.RandomHorizontalFlip(0.5))
return T.Compose(transforms)
trainやevaluateに渡す DataLoaderを作成します。
# use our dataset and defined transformations
dataset = PennFudanDataset('/kqi/input/training', get_transform(train=True))
dataset_test = PennFudanDataset('/kqi/input/training', get_transform(train=False))
# split the dataset in train and test set
torch.manual_seed(1)
indices = torch.randperm(len(dataset)).tolist()
dataset = torch.utils.data.Subset(dataset, indices[:-50])
dataset_test = torch.utils.data.Subset(dataset_test, indices[-50:])
# define training and validation data loaders
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=2, shuffle=True, num_workers=4,
collate_fn=utils.collate_fn)
data_loader_test = torch.utils.data.DataLoader(
dataset_test, batch_size=1, shuffle=False, num_workers=4,
collate_fn=utils.collate_fn)
モデルインスタンスの設定、optimizerの設定をします。
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
# our dataset has two classes only - background and person
num_classes = 2
# get the model using our helper function
model = get_instance_segmentation_model(num_classes)
# move model to the right device
model.to(device)
# construct an optimizer
params = [p for p in model.parameters() if p.requires_grad]
optimizer = torch.optim.SGD(params, lr=0.005,
momentum=0.9, weight_decay=0.0005)
# and a learning rate scheduler which decreases the learning rate by
# 10x every 3 epochs
lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size=3,
gamma=0.1)
いよいよ学習です。
# let's train it for 10 epochs
num_epochs = 10
for epoch in range(num_epochs):
# train for one epoch, printing every 10 iterations
train_one_epoch(model, optimizer, data_loader, device, epoch, print_freq=10)
# update the learning rate
lr_scheduler.step()
# evaluate on the test dataset
evaluate(model, data_loader_test, device=device)
学習実行が最後まで進んだことが確認できます。
Epoch: [9] Total time: 0:00:14 (0.2377 s / it)
creating index...
index created!
Test: [ 0/50] eta: 0:00:11 model_time: 0.0747 (0.0747) evaluator_time: 0.0015 (0.0015) time: 0.2264 data: 0.1488 max mem: 3573
Test: [49/50] eta: 0:00:00 model_time: 0.0447 (0.0448) evaluator_time: 0.0011 (0.0013) time: 0.0492 data: 0.0029 max mem: 3573
Test: Total time: 0:00:02 (0.0541 s / it)
Averaged stats: model_time: 0.0447 (0.0448) evaluator_time: 0.0011 (0.0013)
Accumulating evaluation results...
DONE (t=0.01s).
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.821
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.992
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.951
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.592
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.831
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.378
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.859
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.859
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.775
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.865
# pick one image from the test set
推論を行う
テストデータの一つで実施します。
# pick one image from the test set
img, _ = dataset_test[0]
# put the model in evaluation mode
model.eval()
with torch.no_grad():
prediction = model([img.to(device)])
画像で見る場合は以下で確認できます。
from PIL import ImageDraw
im = Image.fromarray(img.mul(255).permute(1, 2, 0).byte().numpy())
draw = ImageDraw.Draw(im)
draw.rectangle(prediction[0]['boxes'][0].cpu().numpy())
im
おわりに
このように、KAMONOHASHIでは、簡単にGPUが利用可能なJupyter環境を起動し解析を開始できます。
このチュートリアルでは、KAMONOHASHIを用いて、JupyterLab環境でGPUを使用しPenn-Fudanデータセットの人物検出モデルを学習させました。 より詳しくKAMONOHASHIの使い方を知りたい場合はHow-to Guideを参照してください。